Running AI Locally Without Spending All Day on Setup

There are many AI models out there that you can play with from companies like OpenAI, Google, and a host of others. But when you use them, you get the experience they want, and you run it on their computer. There are a variety of reasons you might not like this. You may not want your data or ideas sent through someone else’s computer. Maybe you want to tune and tweak in ways they aren’t going to let you.
There are many more or less open models, but setting up to run them can be quite a chore and — unless you are very patient — require a substantial-sized video card to use as a vector processor. There’s very little help for the last problem. You can farm out processing, but then you might as well use a hosted chatbot. But there are some very easy ways to load and run many AI models on Windows, Linux, or a Mac. One of the easiest we’ve found is Msty. The program is free for personal use and claims to be private, although if you are really paranoid, you’ll want to verify that yourself.
What is Msty?
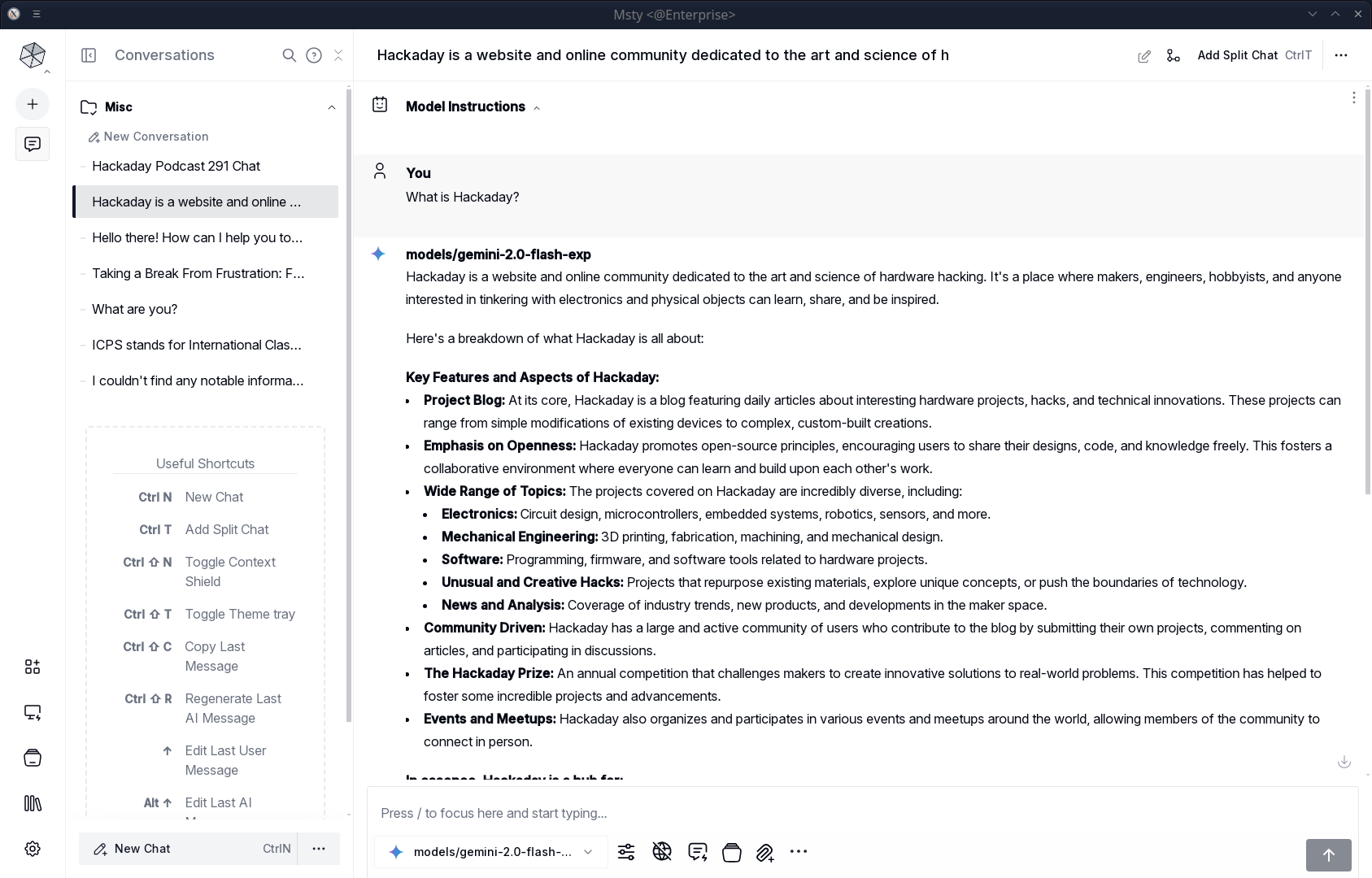
Msty is a desktop application that lets you do several things. First, it can let you chat with an AI engine either locally or remotely. It knows about many popular options and can take your keys for paid services. For local options, it can download, install, and run the engines of your choice.
For services or engines that it doesn’t know about, you can do your own setup, which ranges from easy to moderately difficult, depending on what you are trying to do.
Of course, if you have a local model or even most remote ones, you can use Python or some basic interface (e.g., with ollama; there are plenty of examples). However, Msty lets you have a much richer experience. You can attach files, for example. You can export the results and look back at previous chats. If you don’t want them remembered, you can chat in “vapor” mode or delete them later.
Each chat lives in a folder, which can have helpful prompts to kick off the chat. So, a folder might say, “You are an 8th grade math teacher…” or whatever other instructions you want to load before engaging in chat.
MultiChat
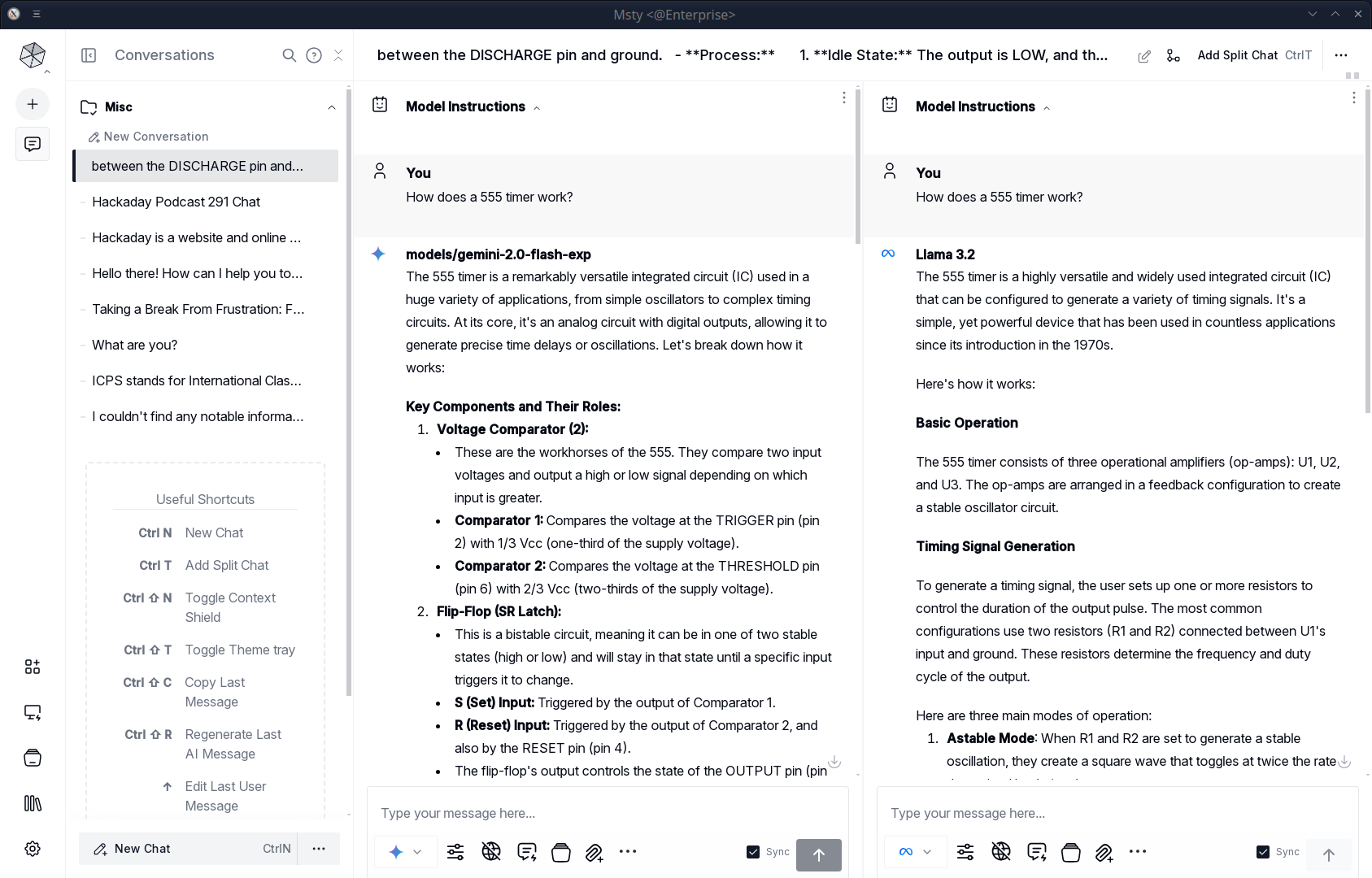
One of the most interesting features is the ability to chat to multiple chatbots simultaneously. Sure, if it were just switching between them, that would be little more than a gimmick. However, you can sync the chats so that each chatbot answers the same prompt, and you can easily see the differences in speed and their reply.
For example, I asked both Google Gemini 2.0 and Llama 3.2 how a 555 timer works, and you can see the answers were quite different.
RAGs
The “knowledge stack” feature lets you easily grab up your own data to use as the chat source (that is RAG or Retrivial Augmented Generation) for use with certain engines. You can add files, folders, Obsidian vaults, or YouTube transcripts.
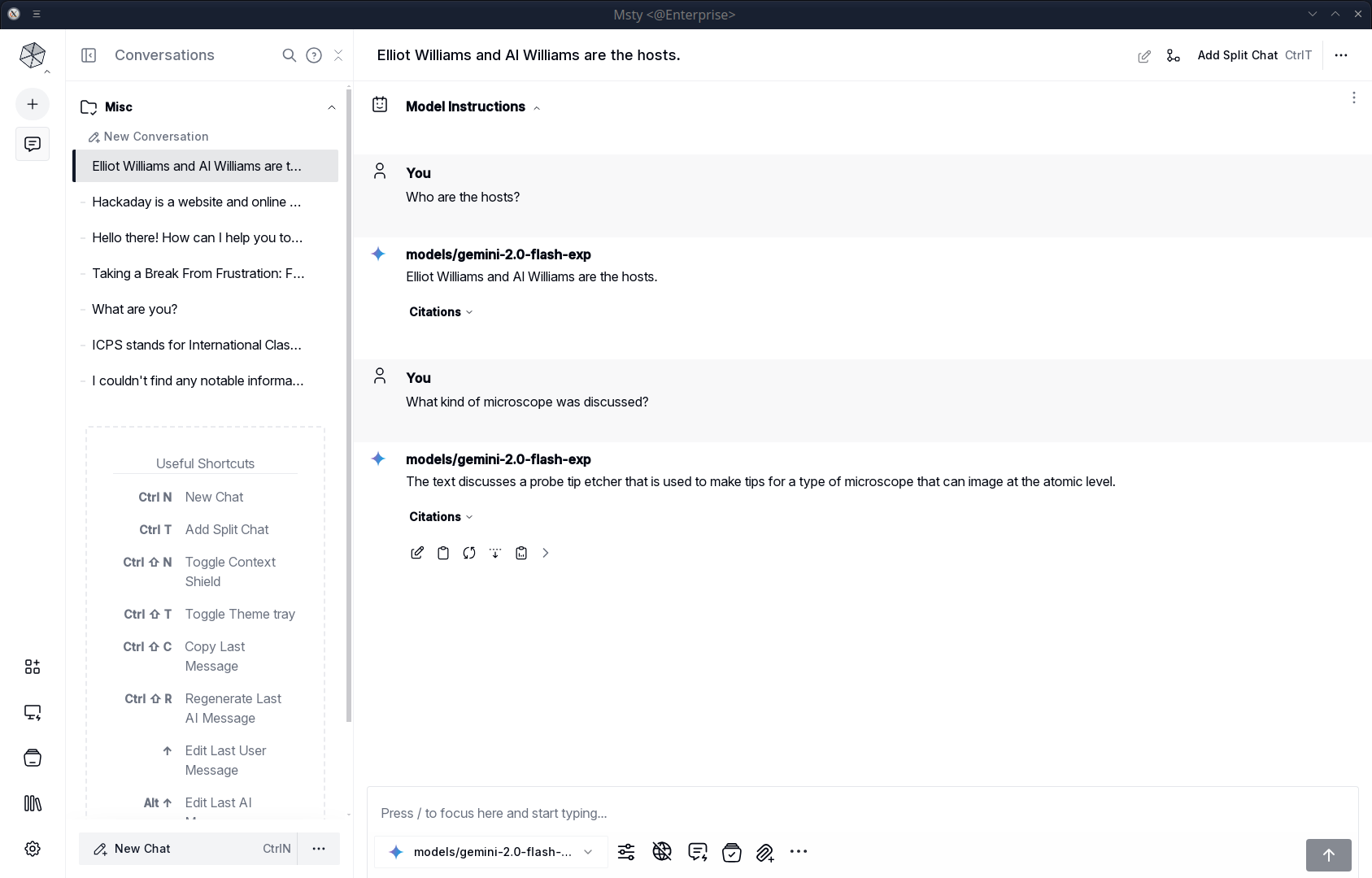
For example, I built a Knowlege Stack named “Hackaday Podcast 291” using the YouTube link. I could then open a chat with Google’s Gemini 2.0 beta (remotely hosted) and chat with the podcast. For example:
You: Who are the hosts?
gemini-2.0-flash-exp: Elliot Williams and Al Williams are the hosts.
You: What kind of microscope was discussed?
gemini-2.0-flash-exp: The text discusses a probe tip etcher that is used to make tips for a type of microscope that can image at the atomic level.
It would be easy to, for example, load up a bunch of PDF data sheets for a processor and, maybe, your design documents to enable discussing a particular project.
You can also save prompts in a library, analyze result metrics, refine prompts and results, and a host of other features. The prompt library has quite a few already available, too, ranging from an acountant to a yogi, if you don’t want to define your own.
New Models
The chat features are great, and having a single interface for a host of backends is nice. However, the best feature is how the program will download, install, run, and shut down local models.
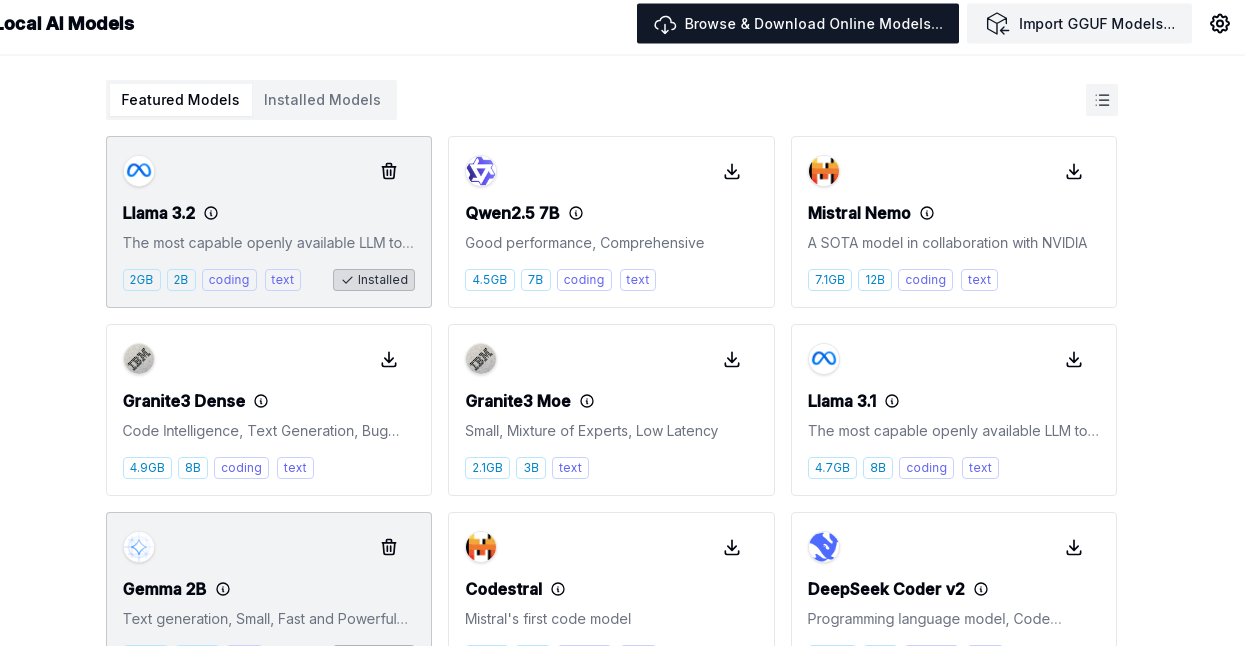
To get started, press the Local AI Model button towards the bottom of the left-hand toolbar. That will give you several choices. Be mindful that many of these are quite large, and some of them require lots of GPU memory.
I started on a machine that had an NVidia 2060 card that had 6GB of memory. Granted, some of that is running the display. But most of it was available. Some of the smaller models would work for a bit, but eventually, I’d get some strange error. That was a good enough excuse to trade up to a 12GB 3060 card, and that seems to be enough for everything I’ve tried so far. Granted, some of the larger models are a little slow, but tolerably so.
There are more options if you press the black button at the top, or you can import GGUF models from places like huggingface. If you’ve already loaded models for something like ollama, you can point Msty at them. You can also point to a local server if you prefer.
The version I tested didn’t know about the Google 2.0 model. However, when adding any of the Google models, it was easy enough to add the (free) API key and the model ID (models/gemini-2.0-flash-exp) for the new model.
Wrap Up
You can spend a lot of time finding and comparing different AI models. It helps to have a list, although you can wait until you’ve burned through the ones Msty already knows about..
Is this the only way to run your own AI model? No, of course not. But it may well be the easiest way we’ve seen. We’d wish for it to be open source, but at least it is free to use for personal projects. What’s your favorite way to run AI? And, yes, we know the answer for some people is “don’t run AI!” That’s an acceptable answer, too.
from Blog – Hackaday https://ift.tt/b0Kdphr



Comments
Post a Comment